How to Determine Which Value of K to Use Kmeans
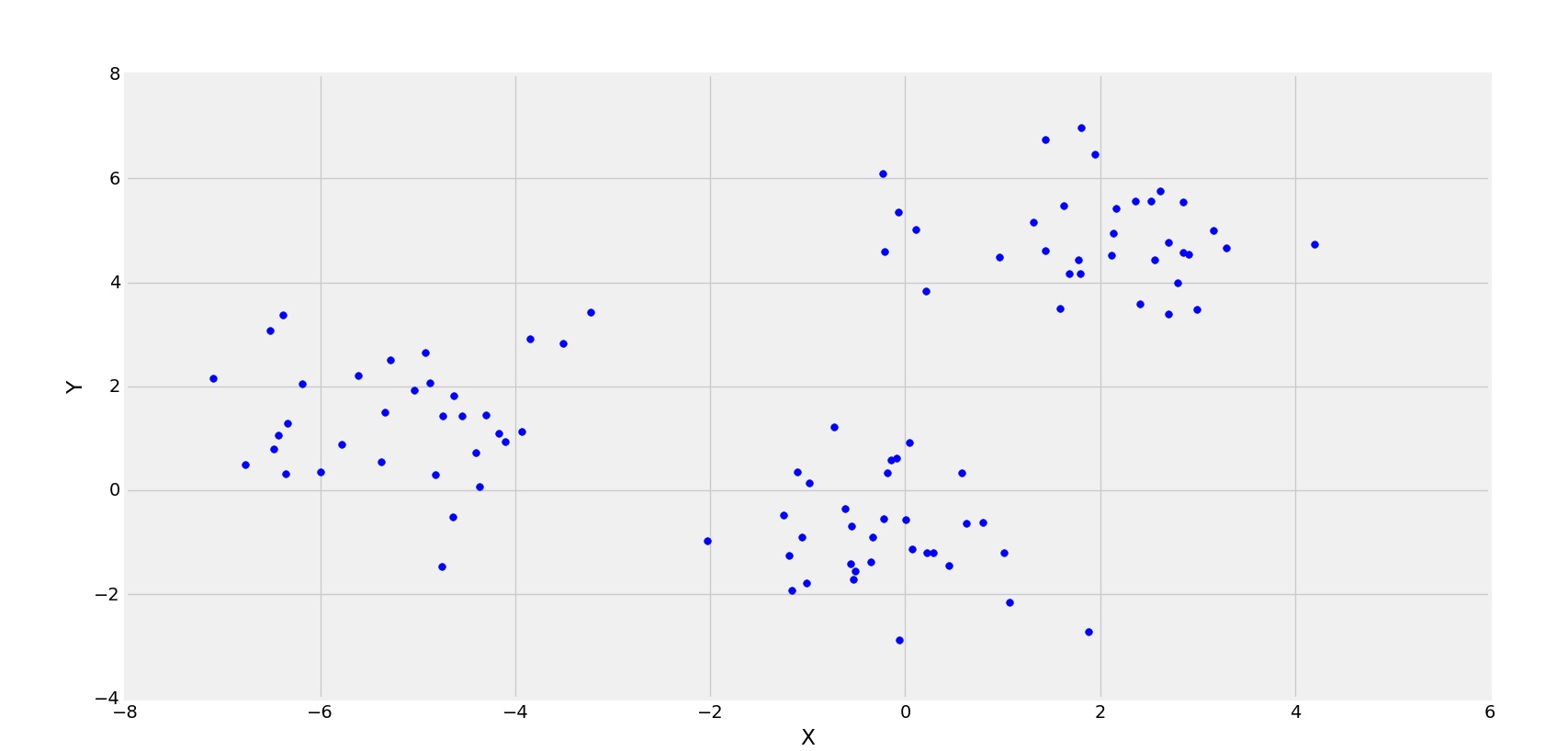
The clustered data points for different value of k-1. In k-means it is essential to provide the numbers of the cluster to form from the dataIn the dataset we knew that there are four clusters.
Ml Determine The Optimal Value Of K In K Means Clustering Geeksforgeeks
We can look at the above graph and say that we need 5 centroids to do K-means clustering.
. It scales well to large number of. Here are some duplicate questions you missed. For each k we calculate the total WSS.
The location where the average silhouette is maximum is considered as optimal value of K. K-means clustering in Python with example. Plots a curve between calculated WCSS values and the number of clusters K.
Perform comparative analysis to determine the best value of K using the Silhouette plot. To determine the optimal number of clusters we have to select the value of k at the elbow ie the point after which the distortioninertia start decreasing in a linear fashion. Then we can visualize the relationship using a line plot to create the elbow plot where we are.
Since clustering algorithms including kmeans use distance-based measurements to determine the similarity between data points its recommended to standardize the data to have a mean of zero and a standard deviation of one since almost. Few things to note here. You can choose the number of clusters by visually inspecting your data points but you will soon realize that there is a lot of ambiguity in this process for all except the simplest data sets.
But when we do not know the number of numbers of the. How to check accuracy for k means algorithm. We construct the following tables for each value of k-k 2.
Choose a value for K. This algorithm requires the number of clusters to be specified. Choosing the Best K Value for K-means Clustering There are many machine learning algorithms used for different applications.
K means finding elbow when the elbow plot is a smooth curve. Some of them are called supervised and some are unsupervised. Compute k-means clustering.
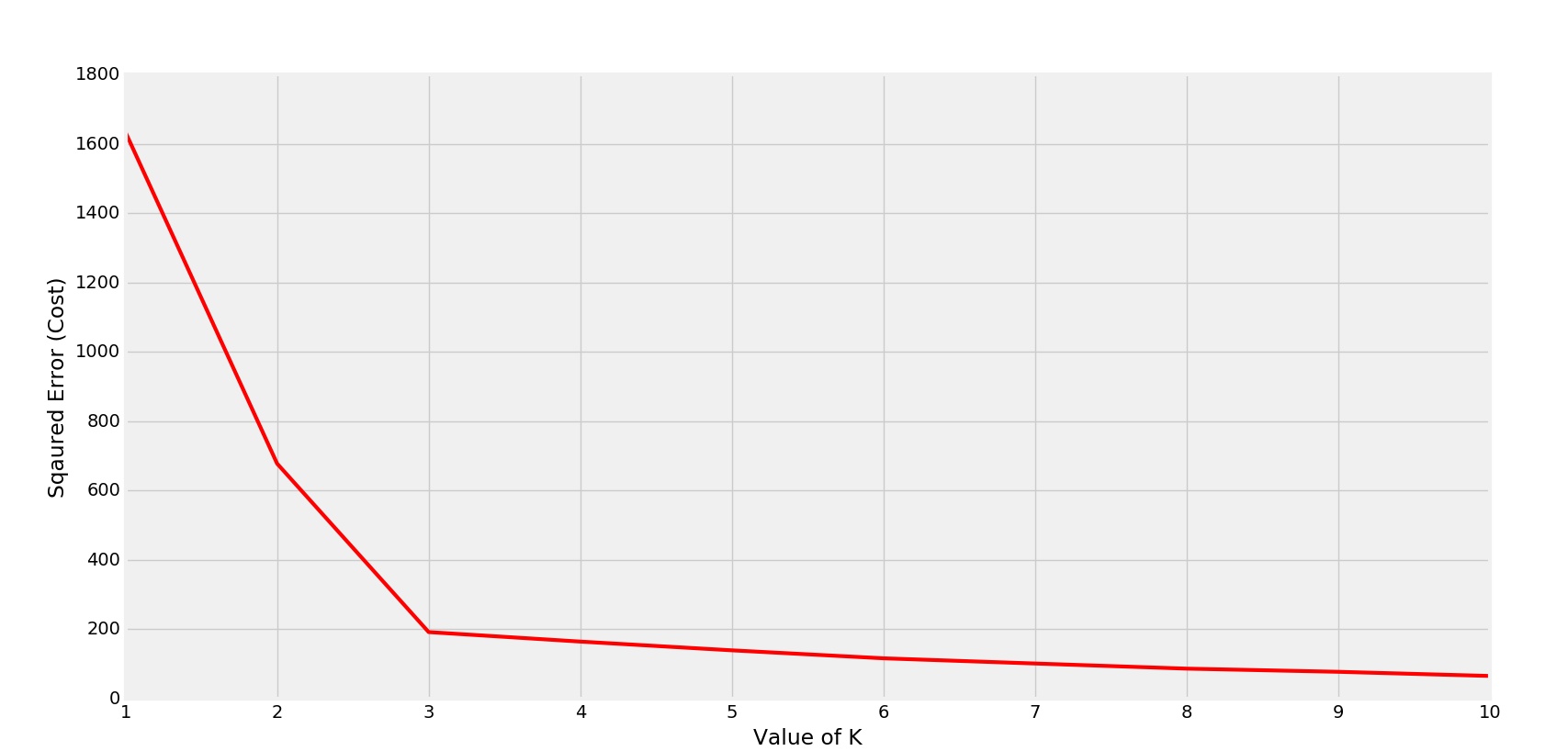
For k varying from 1 to lets say 10 compute the k-means clustering. How to find Optimal K with K-means Clustering. It can be seen below that there is an elbow bend at K5 ie.
In practice we use the following steps to perform K-means clustering. The k from the plot should be chosen such that adding another cluster doesnt. How to optimal K in K - Means Algorithm.
Now use this randomly generated dataset for k-means clustering using KMeans class and fit function available in Python sklearn package. Using K-means with different Ks Total 20 models are created and inertia Silhouette Score and Calinski Harabasz Score scores are. This is not always bad because you are doing unsupervised learning and.
The K-means algorithm clusters the data at hand by trying to separate samples into K groups of equal variance minimizing a criterion known as the inertia or within-cluster sum-of-squares. There are various methods that usually require trying different values of k and measuring which worked best. How to get the total number of values in each clusters in KMeans Algorithm in Pandas.
K 2. Plot the curve of average silhouette score with their respective k values. Kmeans_model KMeans n_clusters 3 random_state 1fit dataframeiloc clusters kmeans_modellabels_count but it is not working.
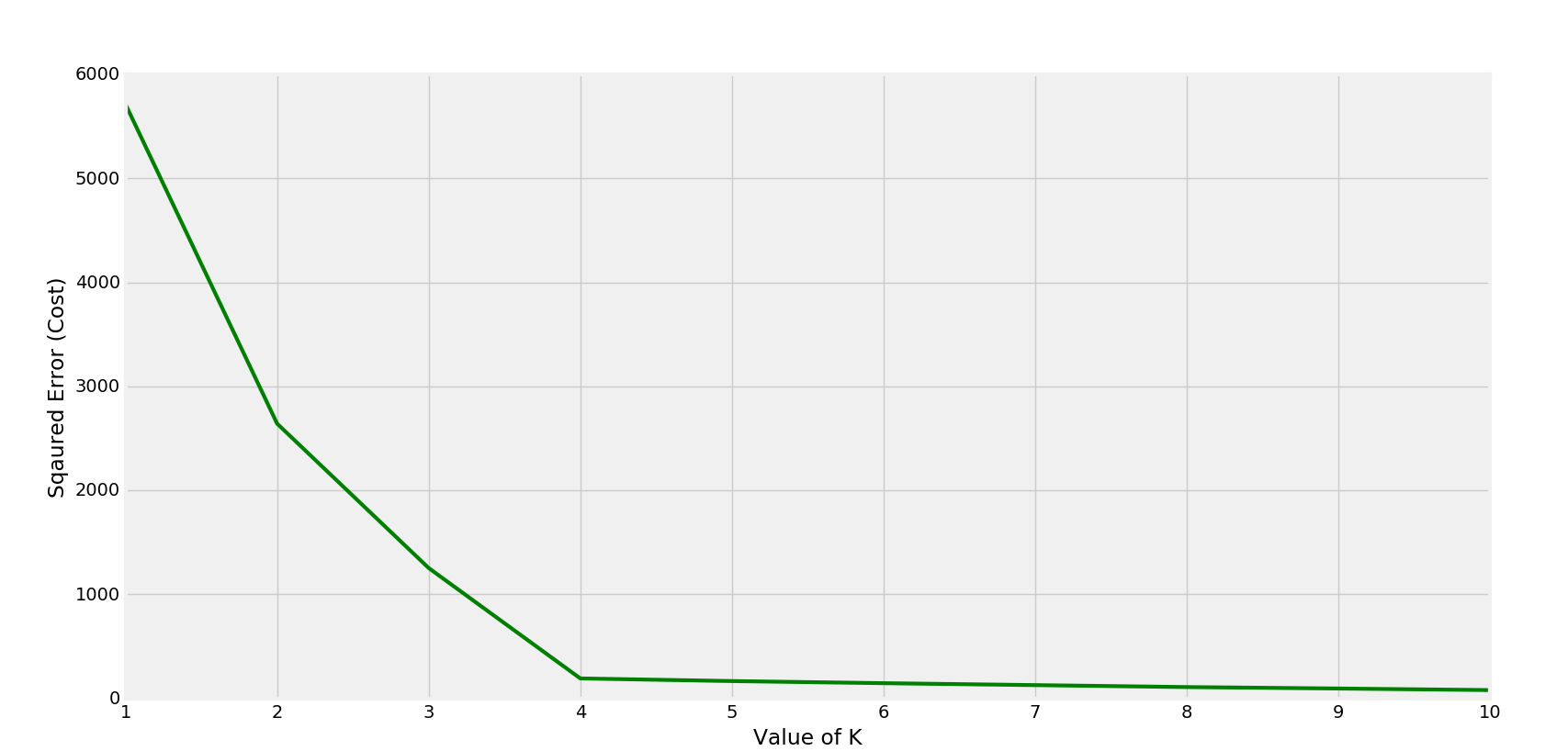
K-means is one of the most widely used unsupervised clustering methods. K 1. Thus for the given data we conclude that the optimal number of clusters for the data is 3.
Calculate Silhouette Score for K-Means Clusters With n_clusters N. The clustered data points for different value of k-1. The steps to determine k using Elbow method are as follows.
First we must decide how many clusters wed like to identify in the data. Answer 1 of 19. Kmeans without knowing the number of clusters.
In a previous post we explained how we can apply the Elbow Method in PythonHere we will use the map_dbl to run kmeans using the scaled_data for k values ranging from 1 to 10 and extract the total within-cluster sum of squares value from each model. KmeansclusterKMeansn_clustersk kmeanskmeansfitdf_scale wss_iter kmeansinertia_ wssappendwss_iter Let us now plot the WCSS vs K cluster graph. Which translates to recomputing the centroid of each cluster to reflect the new assignments.
Krange212 wss for k in K. For each k value we calculate the average silhouette of observations. The appropriate number of clusters k is generally considered where a bend knee is seen in the plot.
We compute cluster using k-means algorithm for different k values vary from 1 to n. We now iterate the values of k from 2 to 5. Often we have to simply test several different values for K and analyze the results to see which number of clusters seems to make the most sense for a given problem.
The last value of k before the slope of the plot levels off suggests a good value of k. It is the point after which WCSS does not diminish much with the increase in value of K. Use map_dbl to run many models with varying value of k centers tot_withinss.
We assume that no practical data exists for which all the data points can be optimally clustered into 1 cluster. Plot the graph of WSS wrt each k.
Ml Determine The Optimal Value Of K In K Means Clustering Geeksforgeeks
Ml Determine The Optimal Value Of K In K Means Clustering Geeksforgeeks

How To Determine The Optimal K For K Means By Khyati Mahendru Analytics Vidhya Medium
No comments for "How to Determine Which Value of K to Use Kmeans"
Post a Comment